正則化
目的関数に正則化項を加えることにより、過学習を防ぐことができます。
一般的な正則化項を用いて目的関数を表してみます。
(1)において、の時をラッソ回帰、
の時をリッジ回帰というのでした。
異なるの値に対する正則化関数のグラフを示します。
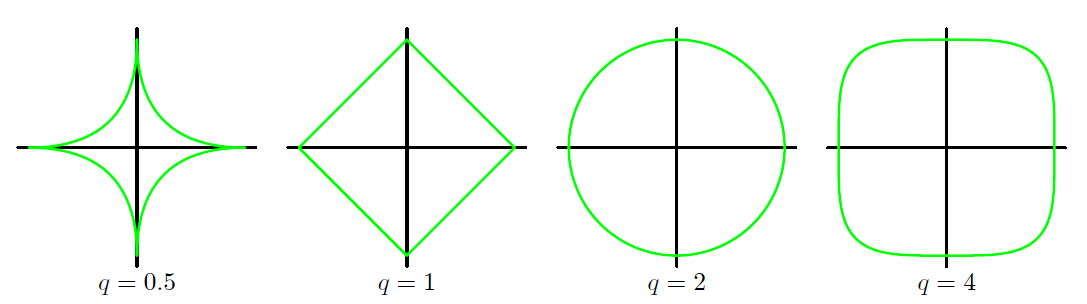
正則化の意味
正則化していない目的関数(2)を、(3)の制約条件の下で最小化することを考えます。
(3)を変形します。
(2)、(4)より、ラグランジュ関数は以下のようになります。
(1)と(5)はに関して同じ式であるので、
(1)をについて最小化するのと、(5)を
について最小化するのは等価です。
(5)の最小化をで考えると、KKT条件より
となることが分かります。(6)では(5)の最小化時のを
としました。
以上の幾何学的解釈が下のグラフです。

ラッソ回帰のパラメータは、疎な解が得られますが
それはグラフからも直感的に解釈することができます。
