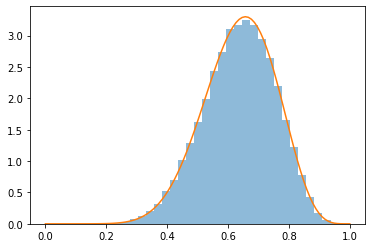
目標分布
目標分布をベータ分布とします。
ベータ分布の描画のためにライブラリを使います。
MCMC時には正規化定数は計算しません。
# 目標分布 def p(x): if x < 0 or 1 < x: return 0 else: return (x ** (a - 1)) * ((1 - x) ** (b - 1)) # カーネルのみを計算

提案分布
提案分布は正規分布の分散が固定のものを採用します。
正規分布の乱数発生はライブラリを使います。
# 乱数発生 def random(mu = 0, sigma = 1): return np.random.normal(mu, sigma) # 正規分布

ソース
############################### # ランダムウォークMH法 ############################### import numpy as np import matplotlib.pyplot as plt from scipy.stats import beta # ベータ関数描画用 # 乱数発生 def random(mu = 0, sigma = 1): return np.random.normal(mu, sigma) # 正規分布 # 目標分布 def p(x): if x < 0 or 1 < x: return 0 else: return (x ** (a - 1)) * ((1 - x) ** (b - 1)) # カーネルのみを計算 # MCMC def MCMC(theta): global received # サンプル候補 a = random(mu = theta, sigma = SIGMA) # a = random(mu = 0, sigma = SIGMA) + theta と書いても同じ # 提案された候補点を確率的に受容し、さもなくばその場に留まる # 補正係数はp(a) / p(θ)である r = p(a) / p(theta) if r > np.random.uniform(0, 1): # 命題が真で確率的に受容する 又は 命題が偽 received += 1 return a else: # 命題が真で確率的に受容しない return theta # ランダムシードを固定 np.random.seed(1) # サンプル数 N = 100000 # バーンイン期間 BURN_IN = 1000 # 提案分布の標準偏差σ SIGMA = 0.2 # 初期値 theta = 0.5 # 受容回数 received = 0 # ベータ分布 a, b = 10.2, 5.8 x = np.linspace(0, 1, 100) # 0 から 1 を 100 分割 y = beta(a, b).pdf(x) # ベータ分布の確率密度関数の値 # 配列を初期化 samples = np.empty(N) # MCMC for i in range(N): theta = MCMC(theta) samples[i] = theta # バーンイン期間のサンプルを捨てる samples = samples[BURN_IN:] # 統計量を比較 # データ print("サンプリング個数: ", len(samples), "個") print("受容確率: ", 100 * received / len(samples), "%") print() # 事後平均値 mu = np.sum(samples) / len(samples); print("サンプリング - 事後期待値: ", mu) print("真の値 - 事後期待値: ", a / (a + b)) print() # 事後分散 v = np.sum((samples - mu) ** 2 ) / len(samples) print("サンプリング - 事後分散: ", v) print("真の値 - 事後分散: ", (a * b) / (((a + b) ** 2) * (a + b + 1))) print() # 事後標準偏差 print("サンプリング - 事後標準偏差: ", v ** 0.5) print("真の値 - 事後標準偏差: ", ((a * b) / (((a + b) ** 2) * (a + b + 1))) ** 0.5) print() # 事後確率最大値 maxIndex = np.argmax((samples ** (a - 1)) * ((1 - samples) ** (b - 1))) print("サンプリング - 事後確率最大値: ", samples[maxIndex]) print("真の値 - 事後確率最大値: ", (a - 1) / (a + b - 2)) print() # 事後中央値 sorted_samples = sorted(samples) if(len(sorted_samples) % 2 != 0):# 奇数 midIndex = int((len(sorted_samples) - 1) / 2) midX = sorted_samples[midIndex] else:# 偶数 midIndex = int(len(sorted_samples) / 2) midX = (sorted_samples[midIndex] + sorted_samples[midIndex - 1]) / 2 print("サンプリング - 事後中央値: ", midX) # np.median(samples)と同じ print("真の値(np) - 事後中央値: ", beta(a, b).median()) print("真の値(wiki) - 事後中央値: ", (a - (1/3)) / (a + b - (2/3) )) # density=True時は、面積が1になるようにする plt.hist(samples, bins = 30, density = True, alpha = 0.5) # プロットする plt.plot(x, y) # 表示する plt.show()