線形回帰再訪
線形回帰モデルにおいて予測分布を考えます。
線形回帰モデルは以下であるとします。
の事前分布は等方的なガウス分布とします。
とします。
は以下のように表せます。
より、
は
を定数行列
で線形変換したものですので、
もまたガウス分布に従います。
この期待値は
です。分散共分散行列は
ここで、は
を要素にもつグラム行列で、はカーネル関数です。
より、
となります。
では、線形回帰モデルにあった重み
は期待値がとられて消えていることに注意してください。
よってこの場合は、線形回帰モデルとは異なりや
の次元がどんなに高くても、
を求める必要はありません。
どんな個の入力の集合
についても、対応する出力
の同時分布
が
多変量ガウス分布に従うとき、と
の関係はガウス過程に従うといいます。
また、多変量ガウス分布において2つの変数の間の共分散が大きいとは、似た値を取りやすいということなので、
すなわち、特徴ベクトルの空間においてと
が似ているなら、対応する
,
も似た値を持つことになります。
ガウス過程のイメージ
ガウス過程とは、無限次元のガウス分布のことだと考えることができます。
無限個の入力に対応してガウス過程に従う無限次元のベクトルを
と書き、
で、平均がのガウス過程を表すことにします。
ここで、はあらゆる入力
の間の共分散を表す無限次元の行列です。
こののうち、観測された有限個の
に限って残りを周辺化し、有限次元のガウス分布としたものが
ということになります。
の3点の場合のガウス過程のイメージを下図に示しました。
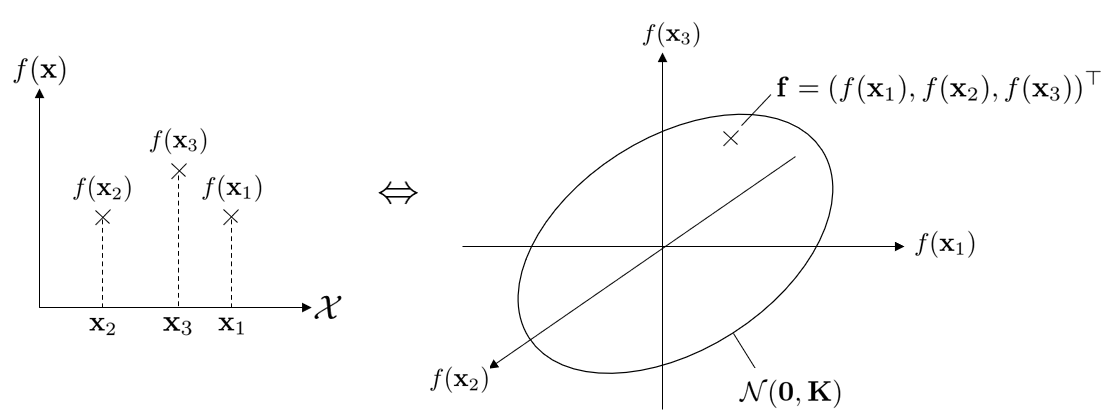
ガウス過程の正確な定義
どんな自然数においても、入力
に対応する出力のベクトル
が平均、
を要素とする行列
を共分散行列とする
ガウス分布に従うとき、
はガウス過程に従うといい、これを
と書きます。
※多くの場合、データを適切に変換することで、は
とみなせますから、
をモデル化する必要は実際にはあまりないようです。
偉人の名言

時計を見るな!
トーマス・エジソン
動画
なし